Dog Breed Classification using Transfer Learning
Use transfer learning on VGG-16 to detect dog breeds
In a previous post, I trained a neural net from scratch to classify dog images using PyTorch. I achieved ~20% accuracy on results, which isn’t great. In this post, my goal is to significantly improve on that accuracy by using Transfer Learning on a pre-trained deeper neural network - VGG-16. The images for the analysis can be downloaded from here.
Transfer learning should be really effective here in training a deep neural net with comparatively little data since it allows us to use a lot of the same information about dog features that VGG-16 has already learned and apply them to a new but similar problem. In other words, for this problem we begin from a good starting point since the model does not have to learn “What is a dog?” or “How is this dog different from that dog?” from scratch.
Initialize Architecture
It is fairly simple to initialize a new architecture that will match our problem. We need to load the pre-trained model and change the last few fully connected layers to get the model output to resemble our target classes. One interesting thing about it is that we don’t need to run backprop on majority of the network since it is already accepted as optimal. In this case, we won’t run backprop on any of the convolutional layers and majority of the fully connected layers. This would make our training really efficient. Let’s look at how we would setup the network in code:
1
2
3
4
5
6
7
8
9
10
def get_model_arch() -> nn.Module:
vgg16 = models.vgg16(pretrained=True)
for param in vgg16.features.parameters():
param.requires_grad = False # pre-trained - dont touch
n_inputs_final_layer = vgg16.classifier[-1].in_features
n_classes = len(self._data_provider.train.dataset.classes)
# Replace the final layer
final_layer = nn.Linear(n_inputs_final_layer, n_classes)
vgg16.classifier[-1] = final_layer
return vgg16
NOTE: We are changing the final layer to resemble our target classes.
Training, Validation, Testing
If you followed my previous post, I defined python classes for data loading, and model training. Since, most of the code looked the same, I refactored it a little bit to handle both 1) training from scratch and 2) training using transfer learning. We define the BaseModel class that handles all of the training, validation and testing code. The derived classes just need to provide properties train_model and test_model.
BaseModel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
class BaseModel(metaclass=abc.ABCMeta):
def __init__(self, data_provider: DataProvider,
save_path: str, **kwargs):
self._data_provider = data_provider
self._save_path = save_path
self._criterion = nn.CrossEntropyLoss()
self._use_gpu = kwargs.pop("use_gpu",
False) and torch.cuda.is_available()
if self._use_gpu:
logger.info("CUDA is enabled - using GPU")
else:
logger.info("GPU Disabled: Using CPU")
self._verbose = kwargs.pop("verbose", False)
@property
@abstractmethod
def train_model(self) -> nn.Module:
raise NotImplementedError("Implement in derived class")
@property
@abstractmethod
def test_model(self) -> nn.Module:
raise NotImplementedError("Implement in base class")
def train(self, n_epochs: int) -> TrainedModel:
model = self.train_model
optimizer = optim.Adam(model.parameters())
logger.info(f"Model Architecture: \n{model}")
validation_losses = []
train_losses = []
min_validation_loss = np.Inf
for epoch in range(n_epochs):
train_loss, validation_loss = self._train_epoch(epoch, model,
optimizer)
validation_losses.append(validation_loss)
train_losses.append(train_loss)
if min_validation_loss > validation_loss:
logger.info(
"Validation Loss Decreased: {:.6f} => {:.6f}. "
"Saving Model to {}".format(
min_validation_loss, validation_loss, self._save_path))
min_validation_loss = validation_loss
torch.save(model.state_dict(), self._save_path)
return TrainedModel(train_losses=train_losses,
validation_losses=validation_losses,
optimal_validation_loss=min_validation_loss)
def _train_epoch(self, epoch: int, neural_net: nn.Module,
optimizer: optim.Optimizer) -> Tuple[float, float]:
train_loss = 0
logger.info(f"[Epoch {epoch}] Starting training phase")
neural_net.train()
total_samples = len(self._data_provider.train.dataset.samples)
batch_count = (total_samples // self._data_provider.train.batch_size)
for batch_index, (data, target) in tqdm(enumerate(
self._data_provider.train), total=batch_count + 1, ncols=80):
if self._use_gpu:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = neural_net(data)
loss = self._criterion(output, target)
loss.backward()
optimizer.step()
train_loss = train_loss + (
(loss.item() - train_loss) / (batch_index + 1))
logger.info(f"[Epoch {epoch}] Starting eval phase")
validation_loss = 0
total_samples = len(self._data_provider.validation.dataset.samples)
batch_count = (
total_samples // self._data_provider.validation.batch_size)
neural_net.eval()
for batch_index, (data, target) in tqdm(enumerate(
self._data_provider.validation), total=batch_count + 1,
ncols=80):
if self._use_gpu:
data, target = data.cuda(), target.cuda()
with torch.no_grad():
output = neural_net(data)
loss = self._criterion(output, target)
validation_loss = validation_loss + (
(loss.item() - validation_loss) / (batch_index + 1))
return train_loss, validation_loss
def test(self) -> TestResult:
model = self.test_model
test_loss = 0
predicted_labels = np.array([])
target_labels = np.array([])
model.eval()
for batch_idx, (data, target) in enumerate(self._data_provider.test):
if self._use_gpu:
data, target = data.cuda(), target.cuda()
output = model(data)
loss = self._criterion(output, target)
test_loss = test_loss + (
(loss.data.item() - test_loss) / (batch_idx + 1))
predicted = output.max(1).indices
predicted_labels = np.append(predicted_labels,
predicted.cpu().numpy())
target_labels = np.append(target_labels, target.cpu().numpy())
return TestResult(test_loss=test_loss,
correct_labels=sum(np.equal(target_labels,
predicted_labels)),
total_labels=len(target_labels))
There are a few more differences in the hyper-parameters of transfer learning model. The normalization means and stds in the new model are: norm_means = [0.485, 0.456, 0.406] and norm_stds = [0.229, 0.224, 0.225]. We are also going to train it for fewer epochs. I chose 6 epochs for my analysis. Below are the training logs for the model:
Training and Validation Logs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
2019-04-04 19:38:03.509 | INFO | breed_classifier:__init__:31 - ROOT_DIR: /data/dog_images/
2019-04-04 19:38:03.509 | INFO | breed_classifier:__init__:32 - BATCH_SIZE: 64
2019-04-04 19:38:03.509 | INFO | breed_classifier:__init__:33 - NUM WORKERS: 0
2019-04-04 19:38:03.553 | INFO | dog_classifier.breed_classifier:__init__:149 - CUDA is enabled - using GPU
2019-04-04 19:38:06.049 | INFO | dog_classifier.breed_classifier:train:168 - Model Architecture:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=133, bias=True)
)
)
2019-04-04 19:38:06.049 | INFO | dog_classifier.breed_classifier:_train_epoch:194 - [Epoch 0] Starting training phase
100%|█████████████████████████████████████████| 105/105 [01:19<00:00, 1.32it/s]
2019-04-04 19:39:25.833 | INFO | dog_classifier.breed_classifier:_train_epoch:210 - [Epoch 0] Starting eval phase
100%|███████████████████████████████████████████| 14/14 [00:08<00:00, 1.62it/s]
2019-04-04 19:39:34.487 | INFO | dog_classifier.breed_classifier:train:180 - Validation Loss Decreased: inf => 1.221989. Saving Model to /home/ksharma/tmp/dog_breed_classifier_transfer.model
2019-04-04 19:39:35.638 | INFO | dog_classifier.breed_classifier:_train_epoch:194 - [Epoch 1] Starting training phase
100%|█████████████████████████████████████████| 105/105 [01:20<00:00, 1.30it/s]
2019-04-04 19:40:56.256 | INFO | dog_classifier.breed_classifier:_train_epoch:210 - [Epoch 1] Starting eval phase
100%|███████████████████████████████████████████| 14/14 [00:08<00:00, 1.59it/s]
2019-04-04 19:41:05.066 | INFO | dog_classifier.breed_classifier:_train_epoch:194 - [Epoch 2] Starting training phase
100%|█████████████████████████████████████████| 105/105 [01:20<00:00, 1.31it/s]
2019-04-04 19:42:25.420 | INFO | dog_classifier.breed_classifier:_train_epoch:210 - [Epoch 2] Starting eval phase
100%|███████████████████████████████████████████| 14/14 [00:08<00:00, 1.60it/s]
2019-04-04 19:42:34.176 | INFO | dog_classifier.breed_classifier:_train_epoch:194 - [Epoch 3] Starting training phase
100%|█████████████████████████████████████████| 105/105 [01:21<00:00, 1.30it/s]
2019-04-04 19:43:55.202 | INFO | dog_classifier.breed_classifier:_train_epoch:210 - [Epoch 3] Starting eval phase
100%|███████████████████████████████████████████| 14/14 [00:08<00:00, 1.60it/s]
2019-04-04 19:44:03.979 | INFO | dog_classifier.breed_classifier:train:180 - Validation Loss Decreased: 1.221989 => 1.152154. Saving Model to /home/ksharma/tmp/dog_breed_classifier_transfer.model
2019-04-04 19:44:05.152 | INFO | dog_classifier.breed_classifier:_train_epoch:194 - [Epoch 4] Starting training phase
100%|█████████████████████████████████████████| 105/105 [01:20<00:00, 1.30it/s]
2019-04-04 19:45:25.865 | INFO | dog_classifier.breed_classifier:_train_epoch:210 - [Epoch 4] Starting eval phase
100%|███████████████████████████████████████████| 14/14 [00:08<00:00, 1.61it/s]
2019-04-04 19:45:34.572 | INFO | dog_classifier.breed_classifier:_train_epoch:194 - [Epoch 5] Starting training phase
100%|█████████████████████████████████████████| 105/105 [01:19<00:00, 1.32it/s]
2019-04-04 19:46:54.352 | INFO | dog_classifier.breed_classifier:_train_epoch:210 - [Epoch 5] Starting eval phase
100%|███████████████████████████████████████████| 14/14 [00:08<00:00, 1.61it/s]
2019-04-04 19:47:03.036 | INFO | dog_classifier.breed_classifier:train:180 - Validation Loss Decreased: 1.152154 => 1.029065. Saving Model to /home/ksharma/tmp/dog_breed_classifier_transfer.model
2019-04-04 19:47:04.199 | INFO | __main__:train:31 - Training Results: TrainedModel(train_losses=[2.771625365529741, 2.0471301839465186, 2.0091793037596197, 1.9197123822711761, 2.043689425786336, 1.8903201120240343], validation_losses=[1.221989027091435, 1.3032183263983048, 1.405754255396979, 1.1521543094090054, 1.1800314315727778, 1.0290648672474032], optimal_validation_loss=1.0290648672474032)
Process finished with exit code 0
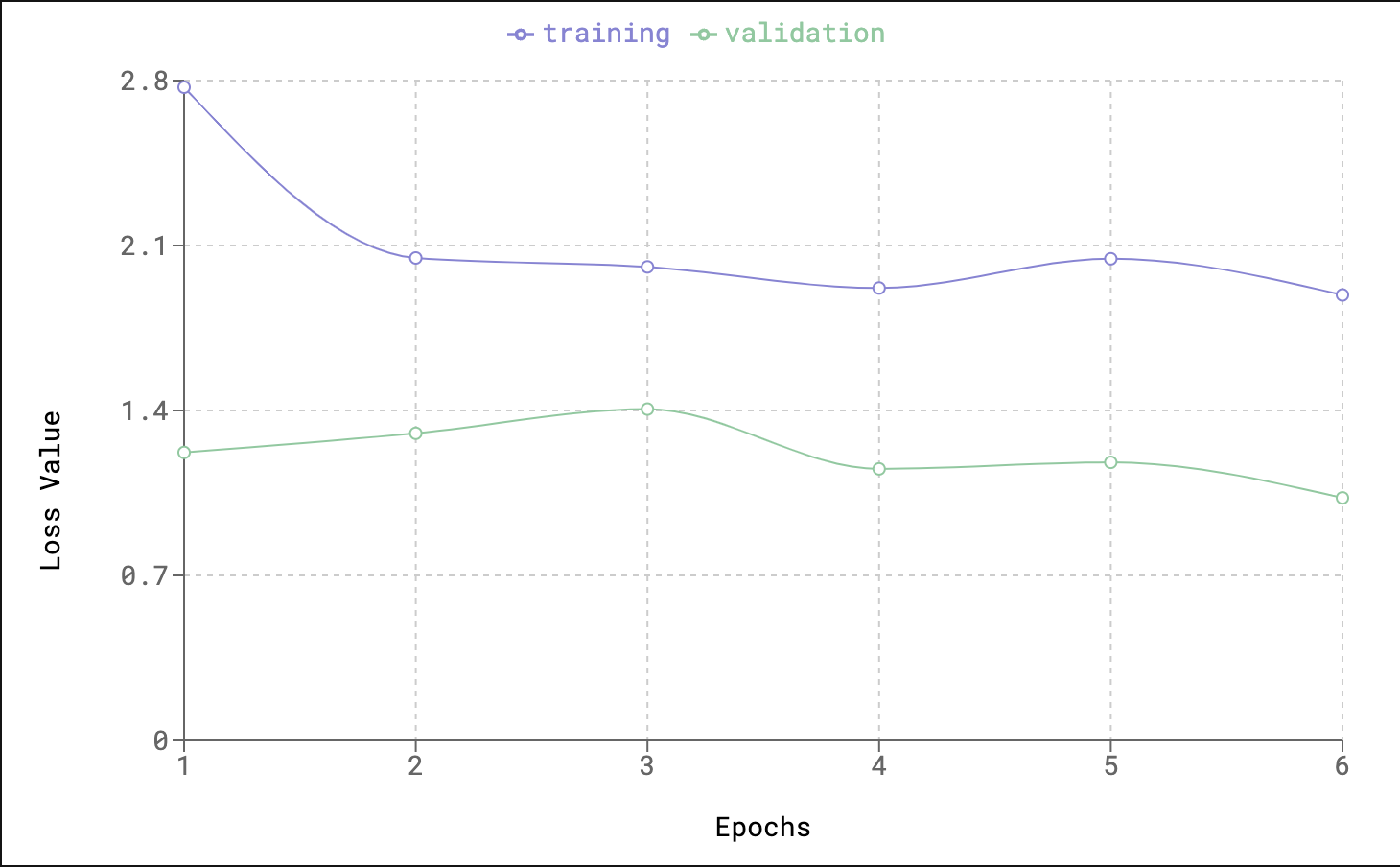
Interestingly, we have a lower loss function value just after epoch 1 compared to the original model I fit from scratch. Our final loss function is way lower than the loss function from the original model. Let’s look at the test results:
Test Logs
1
2
3
4
5
2019-04-04 20:39:40.470 | INFO | breed_classifier:__init__:31 - ROOT_DIR: /data/dog_images/
2019-04-04 20:39:40.470 | INFO | breed_classifier:__init__:32 - BATCH_SIZE: 64
2019-04-04 20:39:40.470 | INFO | breed_classifier:__init__:33 - NUM WORKERS: 0
2019-04-04 20:39:40.509 | INFO | dog_classifier.breed_classifier:__init__:149 - CUDA is enabled - using GPU
2019-04-04 20:39:52.692 | INFO | __main__:test:55 - Test Results: TestResult(test_loss=1.1680023499897547, correct_labels=564, total_labels=836)
NOTE: The test accuracy is almost 67%, way better than 19% from original model
Results
Let’s look at some of the results from our test images. Here is a random collection of 64 images with Red and Green boxes indicating incorrect and correct predictions, respectively:

Below are the worst performing dog breeds in the datasets with their corresponding test accuracy rate.
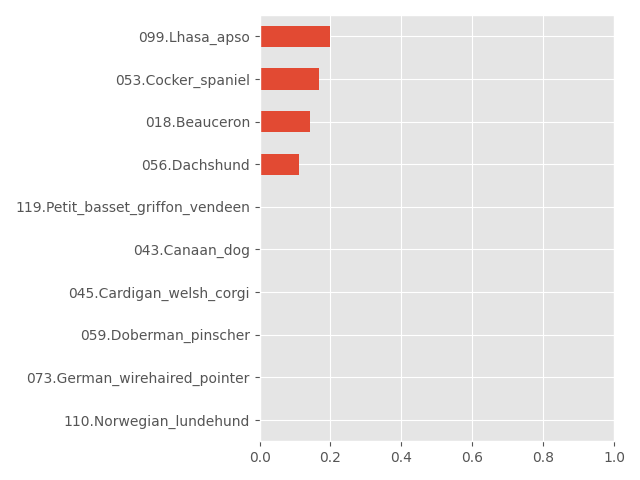




NOTE: On the other hand, 30 breeds had a perfect 100% accuracy
Final Thoughts
In this post, I applied transfer learning to VGG-16 model and used it for dog breed classification. We achieved almost 67% accuracy rate on the test dataset compared to only 19% with the original model from scratch.