Transformers for Recommender Systems - Part 1
Exploring a simple transformer model for sequence modelling in recommender systems
In this post, we will train a transformer model for recommendation systems from scratch. We will use the MovieLens-1M dataset. We will leverage some of the code that we already have for transformers in my previous posts - Post 1 and Post 2.
We will adopt the previous code and modify it to suit the recommendation system use case.
You can refer to my Github repository for the code - Recformers.
Setup
Let’s start by installing the required libraries. I have provided a requirements.txt file in the repository. This was generated via command:
1
conda list -e > requirements.txt
Let’s do all the imports first. It will include some of the modules that we haven’t defined yet. We will in the upcoming sections.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
from imageio.v3 import imread
from collections import Counter
from torch.utils.data import DataLoader
import torch
import torch.nn as nn
from data import MovieLensSequenceDataset
from movielens_transformer import (
MovieLensTransformer,
MovieLensTransformerConfig,
TransformerConfig,
)
import torch.nn.functional as F
from dacite import from_dict
import pprint
from model_train import run_model_training, load_config, get_model_config
from eval import (
get_model_predictions,
get_popular_movies,
get_popular_movie_predictions,
calculate_relevance,
calculate_metrics,
)
from sklearn.metrics import ndcg_score
Movielens Dataset
We will use the MovieLens-1M dataset for this tutorial. You can download the dataset from here. The dataset contains 1 million ratings from 6000 users on 4000 movies. The dataset also contains movie metadata like genres. Let’s explore the dataset.
There are 3 main files in the dataset:
users.dat- Contains user informationratings.dat- Contains user ratings for moviesmovies.dat- Contains movie information
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
users = pd.read_csv(
"./data/ml-1m/users.dat",
sep="::",
names=["user_id", "sex", "age_group", "occupation", "zip_code"],
encoding="ISO-8859-1",
engine="python",
dtype={
"user_id": np.int32,
"sex": "category",
"age_group": "category",
"occupation": "category",
"zip_code": str,
},
)
ratings = pd.read_csv(
"./data/ml-1m/ratings.dat",
sep="::",
names=["user_id", "movie_id", "rating", "unix_timestamp"],
encoding="ISO-8859-1",
engine="python",
dtype={
"user_id": np.int32,
"movie_id": np.int32,
"rating": np.int8,
"unix_timestamp": np.int32,
},
)
movies = pd.read_csv(
"./data/ml-1m/movies.dat",
sep="::",
names=["movie_id", "title", "genres"],
encoding="ISO-8859-1",
engine="python",
dtype={"movie_id": np.int32, "title": str, "genres": str},
)
1
2
3
print(users.head())
print(ratings.head())
print(movies.head())
Users
| user_id | sex | age_group | occupation | zip_code | |
|---|---|---|---|---|---|
| 0 | 1 | F | 1 | 10 | 48067 |
| 1 | 2 | M | 56 | 16 | 70072 |
| 2 | 3 | M | 25 | 15 | 55117 |
| 3 | 4 | M | 45 | 7 | 02460 |
| 4 | 5 | M | 25 | 20 | 55455 |
Ratings
| user_id | movie_id | rating | unix_timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1193 | 5 | 9.78301e+08 |
| 1 | 1 | 661 | 3 | 9.78302e+08 |
| 2 | 1 | 914 | 3 | 9.78302e+08 |
| 3 | 1 | 3408 | 4 | 9.783e+08 |
| 4 | 1 | 2355 | 5 | 9.78824e+08 |
Movies
| movie_id | title | genres | |||
|---|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Animation | Children’s | Comedy |
| 1 | 2 | Jumanji (1995) | Adventure | Children’s | Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy | Romance | |
| 3 | 4 | Waiting to Exhale (1995) | Comedy | Drama | |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
We also downloaded the movie posters for the dataset from a Kaggle dataset. It will be nice to show posters of the movies watched and recommended :). I symlinked these posters to ./data/posters.
1
2
3
4
5
6
7
8
image_urls = [os.path.join("./data/posters", f"{i}.jpg") for i in movies.movie_id]
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
for i, (ax, img) in enumerate(
zip(axs.flat, np.array(image_urls)[[5, 10, 15]].tolist())
):
ax.imshow(imread(img)) # Display the image
ax.axis("off") # Turn off axis
plt.show()

Tokenization
Let’s now tokenize the user_ids and movie_ids such that both map on to 0:N space, where N is the number of unique entities.
1
2
3
4
5
6
7
8
9
10
11
# user ids
unique_user_ids = users["user_id"].unique()
unique_user_ids.sort()
# movie ids
unique_movie_ids = movies["movie_id"].unique()
unique_movie_ids.sort()
# tokenization
user_id_tokens = {user_id: i for i, user_id in enumerate(unique_user_ids)}
movie_id_tokens = {movie_id: i for i, movie_id in enumerate(unique_movie_ids)}
Sequence Generation
We will generate sequences of user_ids and movie_ids for each user. In this part, we will order the movies by timestamp and get full sequence for each user.
1
2
3
4
5
6
7
8
9
10
11
12
ratings["user_id_tokens"] = ratings["user_id"].map(user_id_tokens)
ratings["movie_id_tokens"] = ratings["movie_id"].map(movie_id_tokens)
ratings_ordered = (
ratings[["user_id_tokens", "movie_id_tokens", "unix_timestamp", "rating"]]
.sort_values(by="unix_timestamp")
.groupby("user_id_tokens")
.agg(list)
.reset_index()
)
print(ratings_ordered.head(2))
| user_id_tokens | movie_id_tokens | unix_timestamp | rating | |
|---|---|---|---|---|
| 0 | 0 | [3117, 1672, 1250, 1009, 2271, …] | [978300019, 978300055, 978300055, 978300055, 978300103, …] | [4, 4, 5, 5, 3, …] |
| 1 | 1 | [1180, 1199, 1192, 2648, 1273, …] | [978298124, 978298151, 978298151, 978298196, 978298261, …] | [4, 3, 4, 3, 5, …] |
For the model training, we will feed a sequence movie_ids to the model and predict the next movie_id. Let’s assume we have a sequence_length = 5. Let’s first generate a sequence for one user_id and make sure we generate the correct sequences. Then we can expand that to all the data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
sequence_length = 5
min_sequence_length = 1
window_size = 1
sample_data = ratings_ordered.iloc[0]
sample_movie_ids = torch.tensor(sample_data.movie_id_tokens, dtype=torch.int32)
sample_ratings = torch.tensor(sample_data.rating, dtype=torch.int8)
sample_movie_sequences = (
sample_movie_ids.ravel().unfold(0, sequence_length, 1).to(torch.int32)
)
sample_rating_sequences = (
sample_ratings.ravel().unfold(0, sequence_length, 1).to(torch.int8)
)
print(sample_movie_sequences)
which produces:
1
2
3
4
5
tensor([[3117, 1672, 1250, 1009, 2271],
[1672, 1250, 1009, 2271, 1768],
...
[ 773, 2225, 2286, 1838, 1526],
[2225, 2286, 1838, 1526, 47]], dtype=torch.int32)
This looks good. The movie ids are shifted by 1 in the sequence as we move row by row.
Let’s expand on this and generate sequences for all the users.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def generate_sequences(row, sequence_length, window_size):
movie_ids = torch.tensor(row.movie_id_tokens, dtype=torch.int32)
ratings = torch.tensor(row.rating, dtype=torch.int8)
movie_sequences = (
movie_ids.ravel().unfold(0, sequence_length, window_size).to(torch.int32)
)
rating_sequences = (
ratings.ravel().unfold(0, sequence_length, window_size).to(torch.int8)
)
return (movie_sequences, rating_sequences)
for i, row in ratings_ordered.iterrows():
movie_sequences, rating_sequences = generate_sequences(
row, sequence_length, window_size
)
print(movie_sequences)
print(rating_sequences)
break
1
2
3
4
5
6
tensor([[3117, 1672, 1250, 1009, 2271],
...
[2225, 2286, 1838, 1526, 47]], dtype=torch.int32)
tensor([[4, 4, 5, 5, 3],
...
[4, 5, 4, 4, 5]], dtype=torch.int8)
I have converted all the scrappy code into a proper Dataset class. We will call this MovieLensSequenceDataset. Refer to the code in the repository (data.py) for the full implementation.
1
2
3
4
5
6
7
8
9
10
11
12
13
dataset = MovieLensSequenceDataset(
movies_file="./data/ml-1m/movies.dat",
users_file="./data/ml-1m/users.dat",
ratings_file="./data/ml-1m/ratings.dat",
sequence_length=5,
window_size=1,
)
dataloader = DataLoader(dataset, batch_size=4, shuffle=False)
batch = next(iter(dataloader))
for t in batch:
print(t)
print(t.shape)
print("-----------------------------------")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2024-09-01 06:43:22.424 | INFO | data:__init__:89 - Creating MovieLensSequenceDataset with validation set: %s
2024-09-01 06:43:22.425 | INFO | data:read_movielens_data:12 - Reading data from files
2024-09-01 06:43:24.184 | INFO | data:_add_tokens:140 - Adding tokens to data
2024-09-01 06:43:24.220 | INFO | data:_generate_sequences:159 - Generating sequences
2024-09-01 06:43:24.899 | INFO | data:__init__:110 - Train data length: 883277
2024-09-01 06:43:24.899 | INFO | data:__init__:111 - Validation data length: 98812
tensor([[3883, 3117, 1672, 1250, 1009],
[3117, 1672, 1250, 1009, 2271],
[1672, 1250, 1009, 2271, 1768],
[1250, 1009, 2271, 1768, 3339]], dtype=torch.int32)
torch.Size([4, 5])
-----------------------------------
tensor([[0, 4, 4, 5, 5],
[4, 4, 5, 5, 3],
[4, 5, 5, 3, 5],
[5, 5, 3, 5, 4]], dtype=torch.int8)
torch.Size([4, 5])
-----------------------------------
tensor([0, 0, 0, 0], dtype=torch.int32)
torch.Size([4])
-----------------------------------
tensor([2271, 1768, 3339, 1189], dtype=torch.int32)
torch.Size([4])
-----------------------------------
tensor([3, 5, 4, 4], dtype=torch.int8)
torch.Size([4])
-----------------------------------
Model
Model Definition
Let build the transformer based recommendation model now. We can reuse most of the code that I wrote for my previous post on Exploring GPT. We will skip defining the CausalMultiHeadAttention, MLP, TransformerEncoderLayer (defined as GPT2Layer in previous post), and Transformer (defined as GPT2 in the previous post). Instead, let me just show the differences between what the GPT2 for language model defined vs here.
We will skip the output_layer in the Transformer i.e. just remove it. We need an interaction layer between the movies and users in rec sys model similar to a two tower architecture.
Interaction layer concats the movie embeddings and user embeddings and passes it through an MLP. (similar to the one we defined in DLRM exploration).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class InteractionMLP(nn.Module):
def __init__(self, input_size: int, hidden_sizes: List[int], output_size: int):
super(InteractionMLP, self).__init__()
fc_layers = []
for i, hidden_size in enumerate(hidden_sizes):
if i == 0:
fc_layers.append(nn.Linear(input_size, hidden_size))
else:
fc_layers.append(nn.Linear(hidden_sizes[i - 1], hidden_size))
fc_layers.append(nn.ReLU())
fc_layers.append(
nn.Linear(
hidden_sizes[-1] if hidden_sizes else input_size,
output_size,
bias=False,
)
)
self.fc_layers = nn.Sequential(*fc_layers)
def forward(self, x: torch.Tensor):
return self.fc_layers(x)
Final Movielens RecSys Model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class MovieLensTransformer(nn.Module):
def __init__(self, config: MovieLensTransformerConfig):
super().__init__()
self.movie_transformer = Transformer(config.movie_transformer_config)
self.user_embedding = nn.Embedding(
config.num_users, config.user_embedding_dimension
)
self.output_layer = InteractionMLP(
config.movie_transformer_config.embedding_dimension
+ config.user_embedding_dimension,
config.interaction_mlp_hidden_sizes,
config.movie_transformer_config.vocab_size,
)
def forward(self, movie_ids: torch.Tensor, user_ids: torch.Tensor):
movie_embeddings = self.movie_transformer(movie_ids)
user_embeddings = self.user_embedding(user_ids)
embeddings = torch.cat([movie_embeddings, user_embeddings], dim=-1)
return self.output_layer(embeddings) # returns logits
Quick Test
Next, let’s test the model that we defined to see if we can run a sample batch through it.
Consider a sample model with 2 transformer encoder layers with 2 heads each, embedding dimension of 32, and a user embedding dimension of 32. We will define the model config as below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
movie_ids, ratings, user_ids, output_movie_ids, output_ratings = batch
config_json = {
"movie_transformer_config": {
"vocab_size": len(dataset.metadata.movie_id_tokens),
"context_window_size": 5,
"embedding_dimension": 32,
"num_layers": 2,
"num_heads": 2,
"dropout_embeddings": 0.1,
"dropout_attention": 0.1,
"dropout_residual": 0.1,
"layer_norm_epsilon": 1e-5,
},
"user_embedding_dimension": 32,
"num_users": len(dataset.metadata.user_id_tokens),
"interaction_mlp_hidden_sizes": [16],
}
config = from_dict(data_class=MovieLensTransformerConfig, data=config_json)
Now, let’s construct this model:
1
2
model = MovieLensTransformer(config)
model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
MovieLensTransformer(
(movie_transformer): Transformer(
(token_embedding): Embedding(3885, 32)
(positional_embedding): Embedding(5, 32)
(embedding_dropout): Dropout(p=0.1, inplace=False)
(layers): ModuleList(
(0-1): 2 x TransformerEncoderLayer(
(layer_norm1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(attention): CausalMultiHeadAttention(
(qkv): Linear(in_features=32, out_features=96, bias=True)
(out): Linear(in_features=32, out_features=32, bias=True)
(residual_dropout): Dropout(p=0.1, inplace=False)
)
(layer_norm2): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=32, out_features=128, bias=True)
(activation): GELU(approximate='tanh')
(fc2): Linear(in_features=128, out_features=32, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(layer_norm): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
)
(user_embedding): Embedding(6040, 32)
(output_layer): InteractionMLP(
(fc_layers): Sequential(
(0): Linear(in_features=320, out_features=16, bias=True)
(1): ReLU()
(2): Linear(in_features=16, out_features=3885, bias=False)
)
)
)
1
2
3
4
logits = model(movie_ids=movie_ids, user_ids=user_ids)
logits.shape
# torch.Size([4, 3885])
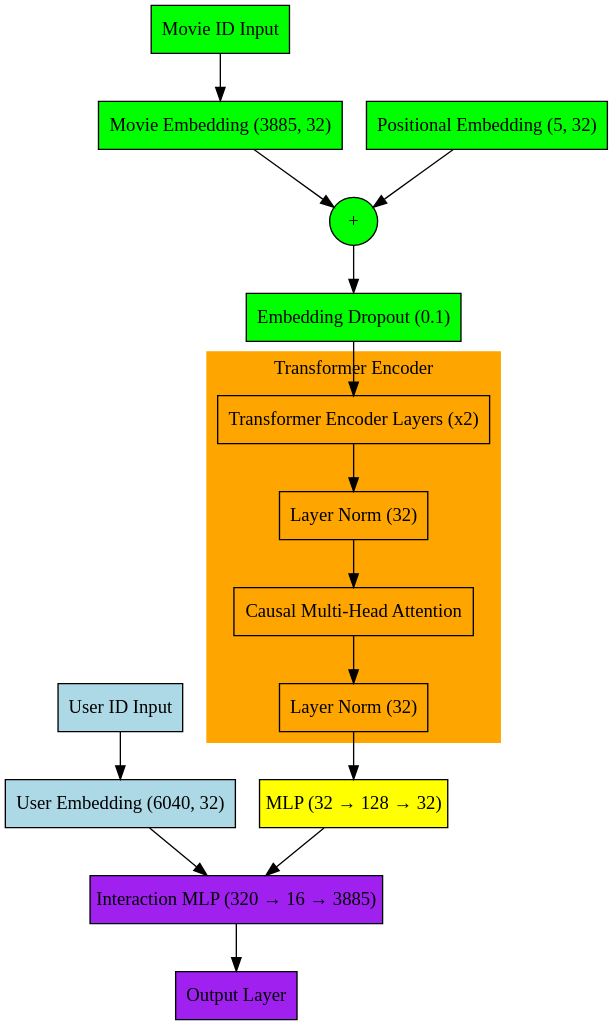
Model Graph
For quick visualization, I used digraph to generate the model graph:
Training
We are able to run the model end to end! Now, let’s setup the weight initialization for the model.
1
2
3
4
5
6
7
8
9
def init_weights(model: MovieLensTransformer):
initrange = 0.1
model.movie_transformer.token_embedding.weight.data.uniform_(-initrange, initrange)
model.user_embedding.weight.data.uniform_(-initrange, initrange)
for name, p in model.output_layer.named_parameters():
if "weight" in name:
p.data.uniform_(-initrange, initrange)
elif "bias" in name:
p.data.zero_()
Train step
Now that we have the model defined and weights initialization done, we should be able to define a train step. Let’s follow the sage advice from karpathy and try to overfit one batch.
Overfit one batch
1
print(batch)
1
2
3
4
5
6
7
8
9
10
11
[tensor([[3883, 3117, 1672, 1250, 1009],
[1672, 1250, 1009, 2271, 1768],
[1250, 1009, 2271, 1768, 3339],
[2271, 1768, 3339, 1189, 2735]], dtype=torch.int32),
tensor([[0, 4, 4, 5, 5],
[4, 5, 5, 3, 5],
[5, 5, 3, 5, 4],
[3, 5, 4, 4, 5]], dtype=torch.int8),
tensor([0, 0, 0, 0], dtype=torch.int32),
tensor([2271, 3339, 1189, 257], dtype=torch.int32),
tensor([3, 4, 4, 4], dtype=torch.int8)]
We will use CrossEntropyLoss for the loss function and Adam for the optimizer. Refer to previous posts for more context on loss function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
movie_ids, user_ids, output_movie_ids = (
movie_ids.to(device),
user_ids.to(device),
output_movie_ids.to(device),
)
epochs = 10000
for epoch in range(epochs):
optimizer.zero_grad()
logits = model(movie_ids=movie_ids, user_ids=user_ids)
loss = criterion(
logits.view(-1, logits.shape[-1]), output_movie_ids.view(-1).long()
)
loss.backward()
optimizer.step()
if epoch % 1000 == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
1
2
3
4
5
6
7
8
9
10
Epoch 0, Loss: 8.441213607788086
Epoch 1000, Loss: 0.0002911832998506725
Epoch 2000, Loss: 7.801931496942416e-05
Epoch 3000, Loss: 3.2334930438082665e-05
Epoch 4000, Loss: 1.6748752386774868e-05
Epoch 5000, Loss: 7.867780368542299e-06
Epoch 6000, Loss: 4.321327196521452e-06
Epoch 7000, Loss: 2.2947760953684337e-06
Epoch 8000, Loss: 1.1324875686113955e-06
Epoch 9000, Loss: 7.152555099310121e-07
Let’s now generate the next token from this overfit model to check if it matches the batch target tensor.
1
2
3
4
5
6
7
8
model.eval()
logits = model(movie_ids=movie_ids, user_ids=user_ids)
print(logits)
# logits -> token probabilities
probabilities = F.softmax(logits, dim=-1)
print(torch.argmax(probabilities, dim=-1))
print(output_movie_ids)
1
2
3
4
5
6
7
tensor([[-10.5723, -12.5562, -5.7962, ..., -7.3221, -13.8760, -4.5341],
[-15.7002, -18.1513, -2.9636, ..., -14.8108, -15.4972, -3.4746],
[-10.2821, -15.7702, -6.5699, ..., -8.4564, -5.2607, -3.0306],
[ -6.7581, -7.9105, -3.9927, ..., -9.7447, -5.7057, -7.2526]],
device='cuda:0', grad_fn=<MmBackward0>)
tensor([2271, 3339, 1189, 257], device='cuda:0')
tensor([2271, 3339, 1189, 257], device='cuda:0', dtype=torch.int32)
They match perfectly!
Nice! So, we can see the model has fully overfit the specific batch and model training run passes the smell check.
Next, we will define the full training loop. We will also add a validation loop to test of validation loss and checkpoint model when validation loss improves.
Train Step
Based on the test above, we can define the train step as below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def train_step(
movie_ids: torch.Tensor,
user_ids: torch.Tensor,
movie_targets: torch.Tensor,
model: nn.Module,
optimizer: torch.optim.Optimizer,
criterion: torch.nn.Module,
device: torch.device,
):
movie_ids, user_ids, movie_targets = (
movie_ids.to(device),
user_ids.to(device),
movie_targets.to(device),
)
optimizer.zero_grad()
output = model(movie_ids, user_ids)
loss = criterion(output.view(-1, output.size(-1)), movie_targets.view(-1).long())
loss.backward()
optimizer.step()
return loss.item()
Validation step
Similarly, we can define the validation step to test the model on the validation set:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def validation_step(
movie_ids: torch.Tensor,
user_ids: torch.Tensor,
movie_targets: torch.Tensor,
model: nn.Module,
criterion: torch.nn.Module,
device: torch.device,
):
movie_ids, user_ids, movie_targets = (
movie_ids.to(device),
user_ids.to(device),
movie_targets.to(device),
)
with torch.no_grad():
output = model(movie_ids, user_ids)
loss = criterion(
output.view(-1, output.size(-1)), movie_targets.view(-1).long()
)
return loss.item()
Dataset
1
2
3
4
5
6
7
8
9
10
11
12
13
def get_dataset(config) -> Dataset:
movies_file = os.path.join(config["trainer_config"]["data_dir"], "movies.dat")
users_file = os.path.join(config["trainer_config"]["data_dir"], "users.dat")
ratings_file = os.path.join(config["trainer_config"]["data_dir"], "ratings.dat")
dataset = MovieLensSequenceDataset(
movies_file=movies_file,
users_file=users_file,
ratings_file=ratings_file,
sequence_length=config["movie_transformer_config"]["context_window_size"],
window_size=1, # next token prediction with sliding window of 1
)
return dataset
Using all the code above, full training loop has been defined in model_train.py in the repo. Most of this code is boilerplate. So, I will not go into details here.
NOTE: I have added tensorflow logging to the training loop. We will use it later to visualize the loss values.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
def run_model_training(config: dict):
device = config["trainer_config"]["device"]
if device == "cuda" and not torch.cuda.is_available():
raise ValueError("CUDA is not available")
dataset = get_dataset(config)
train_dataloader = DataLoader(
dataset, batch_size=config["trainer_config"]["batch_size"], shuffle=True
)
validation_dataloader = DataLoader(
dataset, batch_size=config["trainer_config"]["batch_size"], shuffle=False
)
model_config = get_model_config(config, dataset)
model = MovieLensTransformer(config=model_config)
init_weights(model)
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=config["trainer_config"]["starting_learning_rate"]
)
best_validation_loss = np.inf
writer = SummaryWriter(
log_dir=config["trainer_config"]["tensorboard_dir"], flush_secs=30
)
for epoch in range(config["trainer_config"]["num_epochs"]):
model.train()
total_loss = 0.0
pbar = trange(len(train_dataloader))
pbar.ncols = 150
for i, (
movie_ids,
rating_ids,
user_ids,
movie_targets,
rating_targets,
) in enumerate(train_dataloader):
loss = train_step(
movie_ids,
user_ids,
movie_targets,
model,
optimizer,
criterion,
device,
)
total_loss += loss
pbar.update(1)
pbar.set_description(
f"[Epoch = {epoch}] Current training loss (loss = {np.round(loss, 4)})"
)
pbar.refresh()
pbar.close()
train_loss = total_loss / len(train_dataloader)
logger.info(f"Epoch {epoch}, Loss: {np.round(train_loss, 4)}")
writer.add_scalar("loss/train", train_loss, epoch)
model.eval()
total_loss = 0.0
pbar = trange(len(validation_dataloader))
pbar.ncols = 150
for i, (
movie_ids,
rating_ids,
user_ids,
movie_targets,
rating_targets,
) in enumerate(validation_dataloader):
loss = validation_step(
movie_ids,
user_ids,
movie_targets,
model,
criterion,
device,
)
total_loss += loss
pbar.update(1)
pbar.set_description(
f"[Epoch = {epoch}] Current validation loss (loss = {np.round(loss, 4)})"
)
pbar.refresh()
pbar.close()
validation_loss = total_loss / len(validation_dataloader)
logger.info(f"Validation Loss: {np.round(validation_loss, 4)}")
writer.add_scalar("loss/validation", validation_loss, epoch)
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
if not os.path.exists(config["trainer_config"]["model_dir"]):
os.makedirs(config["trainer_config"]["model_dir"])
torch.save(
model.state_dict(),
os.path.join(config["trainer_config"]["model_dir"], "model.pth"),
)
Let’s test this with a single epoch run!
1
2
3
config_file = "./training_config.yaml"
config = load_config(config_file)
config["trainer_config"]["num_epochs"] = 1
1
run_model_training(config)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2024-09-01 05:34:43.708 | INFO | data:__init__:89 - Creating MovieLensSequenceDataset with validation set: %s
2024-09-01 05:34:43.708 | INFO | data:read_movielens_data:12 - Reading data from files
2024-09-01 05:34:45.536 | INFO | data:_add_tokens:140 - Adding tokens to data
2024-09-01 05:34:45.572 | INFO | data:_generate_sequences:159 - Generating sequences
2024-09-01 05:34:46.203 | INFO | data:__init__:110 - Train data length: 884050
2024-09-01 05:34:46.203 | INFO | data:__init__:111 - Validation data length: 98039
2024-09-01 05:34:46.204 | INFO | model_train:get_model_config:98 - Model config:
==========
MovieLensTransformerConfig(movie_transformer_config=TransformerConfig(vocab_size=3885, context_window_size=5, embedding_dimension=32, num_layers=4, num_heads=4, dropout_embeddings=0.1, dropout_attention=0.1, dropout_residual=0.1, layer_norm_epsilon=1e-05), user_embedding_dimension=32, num_users=6040, interaction_mlp_hidden_sizes=[16])
==========
[Epoch = 0] Current training loss (loss = 7.295): 100%|██████████████████████████████████████████████████████████| 1727/1727 [00:11<00:00, 155.17it/s]
2024-09-01 05:34:57.343 | INFO | model_train:run_model_training:164 - Epoch 0, Loss: 7.4376
[Epoch = 0] Current validation loss (loss = 7.2114): 100%|███████████████████████████████████████████████████████| 1727/1727 [00:06<00:00, 256.52it/s]
2024-09-01 05:35:04.077 | INFO | model_train:run_model_training:197 - Validation Loss: 7.1828
Awesome! It is working. Let us now run a full training run for 1000 epochs. I ran the full training run and collected the loss values for training and validation using tensorboard. Let’s look at these loss values:
1
2
3
4
5
6
7
from tbparse import SummaryReader
log_dir = config["trainer_config"]["tensorboard_dir"]
reader = SummaryReader(log_dir)
metrics = reader.scalars
print(metrics.head())
metrics.groupby(["step", "tag"]).mean().unstack()["value"].plot()
| step | tag | value | |
|---|---|---|---|
| 0 | 0 | loss/train | 7.41048 |
| 1 | 0 | loss/train | 7.37051 |
| 2 | 0 | loss/train | 7.38262 |
| 3 | 0 | loss/train | 7.34704 |
| 4 | 0 | loss/train | 7.4013 |
Loss Values
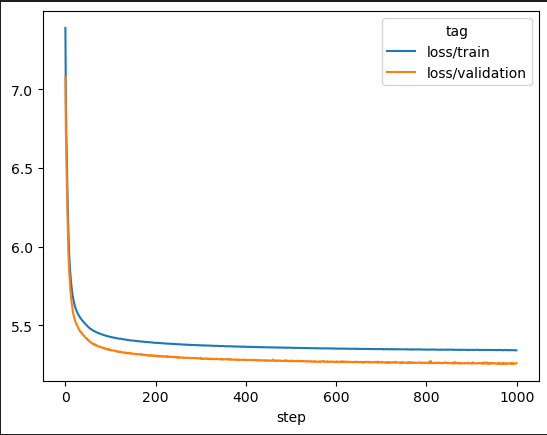
We can see that the model has learnt a lot already. Looking at the last few loss values, it seems that the model is still learning but it is good enough for now for our next steps.
Model Predictions
Trained model is available at movielens-ntp/models/model_1000e_512_32_32_4_4.pth. We will use this to generate next movie prediction.
Next Token Prediction
A simple way to get the topmost movie recommended is to get the token corresponding to the maximum probability. We apply softmax to the logits to get the probability and use argmax to get the corresponding token.
Let’s look at some sample code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
trained_model_state_dict = torch.load("./models/model_1000e_512_32_32_4_4.pth")
model_config = get_model_config(config, test_dataset)
trained_model = MovieLensTransformer(model_config)
trained_model.load_state_dict(trained_model_state_dict)
def predict_next_movie(model, movie_ids, user_ids):
model.eval()
logits = model(movie_ids=movie_ids, user_ids=user_ids)
probabilities = F.softmax(logits, dim=-1)
predicted_movie_ids = torch.argmax(probabilities, dim=-1)
print(predicted_movie_ids)
return predicted_movie_ids
# test_batch from dataloader
movie_ids, rating_ids, user_ids, movie_targets, rating_targets = test_batch
predicted_movie_ids = predict_next_movie(trained_model, movie_ids, user_ids)
1
2
tensor([2381, 2847, 2, 93, 2300, 3460, 588, 583, 651, 2401, 2789, 2428,
584, 1575, 1023, 351])
Let’s visualize these prediction using our movie posters:
1
2
merged = torch.cat([movie_ids, predicted_movie_ids.view(-1, 1)], dim=1)
merged
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
tensor([[1763, 2379, 2632, 1352, 1984, 2381],
[1852, 2847, 1081, 31, 1543, 2847],
[1050, 228, 516, 2655, 817, 2],
[1356, 1556, 349, 2951, 372, 93],
[1931, 1019, 2233, 1429, 2178, 2300],
[1548, 363, 1444, 986, 2916, 3460],
[ 188, 2872, 427, 2315, 1278, 588],
[1854, 360, 2428, 230, 2358, 583],
[2559, 1534, 2126, 1084, 1499, 651],
[1085, 2401, 1942, 3379, 1932, 2401],
[2063, 2557, 1291, 510, 2429, 2789],
[1819, 1430, 267, 205, 1564, 2428],
[1482, 1726, 3088, 2252, 2286, 584],
[2269, 2038, 589, 3878, 1575, 1575],
[ 158, 2335, 542, 2125, 453, 1023],
[ 431, 3495, 1471, 1600, 1969, 351]])
Get Poster paths
1
2
3
4
5
6
7
8
9
10
11
rows, columns = merged.shape
movie_image_files = []
token_to_movie = {v: k for k, v in test_dataset.metadata.movie_id_tokens.items()}
for row in range(rows):
movie_image_files.append(
[
f"./data/posters/{token_to_movie[image_token.item()]}.jpg"
for image_token in merged[row]
]
)
Movie Recommendations
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
for image_row in movie_image_files:
fig, axs = plt.subplots(1, columns, figsize=(18, 5))
for i, (ax, img) in enumerate(zip(axs.flat, image_row)):
if os.path.exists(img):
ax.imshow(imread(img))
if i == columns - 1:
ax.patch.set_edgecolor("red")
ax.patch.set_linewidth(3)
# ax.axis("off") # Turn off axis
ax.set_aspect("equal")
ax.set_title(os.path.basename(img).split(".")[0])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.subplots_adjust(wspace=0, hspace=0)
plt.show()




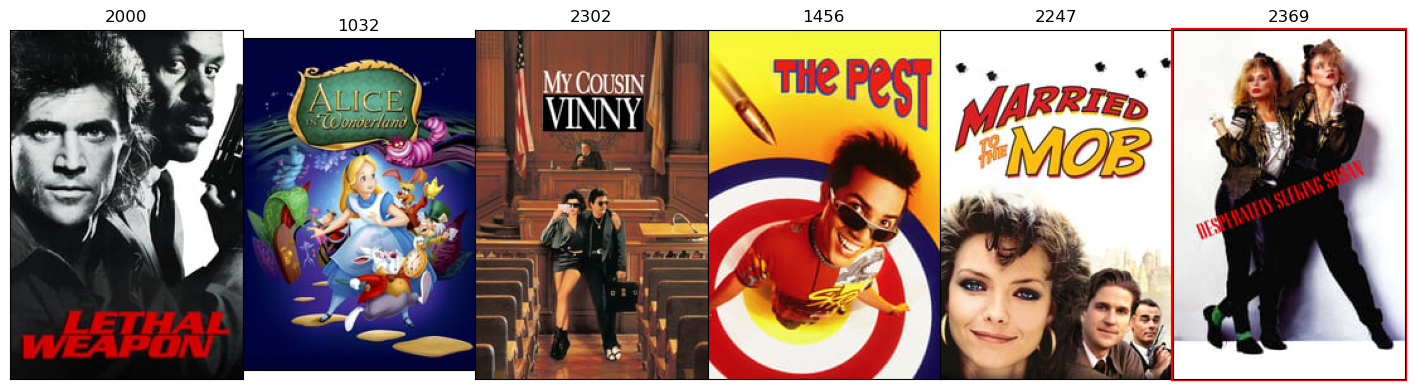











Analysis
Based on my limited movie watching experience, I can see some good recommendations in the above list. We can see that model learns to recommend movies based on the user’s previous movie watching history.
For example,
- Sci-fi movies are followed by sci-fi movies
- Animated movies are followed by animated movies
- Action movies are followed by action movies
In some case, we also see that the movies recommended are also present in the previous context. We will tackle this later but it is good sign since model is able to identify user interests.
For a proper model quality analysis, we will look into metrics next.
Metrics
In reality, we will recommend a few movies to the user and not just one. In addition, if we are using this model as a retrieval model, we would get a few recommendations to feed it to the (re)-ranker.
NOTE: The discussion around retrieval and re-ranking are beyond the scope of this post. We will focus on the model quality metrics here. May be, some day I will do a proper post on multi-stage ranking pipelines but today is not that day. ¯\_(ツ)_/¯
Next, we will look at the quality of the model predictions. There are several different categories of metrics that we can look at.
Prediction Quality
To assess whether the model is making accurate predictions, the common metrics that are used include:
- Precision @ K
- Recall @ K
- F-score
Ranking Quality
To assess the quality of ranked results, common metrics include:
- MRR (Mean Reciprocal Rank)
- MAP (Mean Average Precision)
- Hit Rate @ K
- NDCG (Normalized Discounted Cumulative Gain)
Behavioral
To further improve user experience, few metrics that go beyond just model accuracy include:
- Diversity
- Novelty
- Serendipity
- Popularity Bias
Since, we are doing single prediction at a time, some of the prediction quality metrics end up being equivalent to ranking quality metrics. We will focus on the ranking quality metrics here.
Baseline Model
To compare our current model, we need a baseline prediction model. As a baseline, we can suggest just the most popular movies to the user i.e. show the movies with highest average ratings that the user hasn’t seen. We can also add restrictions around movies that have been rated the most such that averages are statistically significant.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
ratings = pd.read_csv(
"./data/ml-1m/ratings.dat",
sep="::",
names=["user_id", "movie_id", "rating", "unix_timestamp"],
encoding="ISO-8859-1",
engine="python",
dtype={
"user_id": np.int32,
"movie_id": np.int32,
"rating": np.float16,
"unix_timestamp": np.int32,
},
)
rating_counts = ratings["movie_id"].value_counts().reset_index()
rating_counts.columns = ["movie_id", "rating_count"]
# Get the most frequently rated movies
min_ratings_threshold = rating_counts["rating_count"].quantile(0.95)
# Filter movies based on the minimum number of ratings
popular_movies = ratings.merge(rating_counts, on="movie_id")
popular_movies = popular_movies[popular_movies["rating_count"] >= min_ratings_threshold]
# Calculate the average rating for each movie
average_ratings = popular_movies.groupby("movie_id")["rating"].mean().reset_index()
# Get the top 5 rated movies
top_5_movies = list(
average_ratings.sort_values("rating", ascending=False).head(5).movie_id.values
)
top_5_movies
# [318, 858, 50, 527, 1198]
Let’s visualize them
1
2
3
4
5
6
7
8
9
10
11
fig, axs = plt.subplots(1, len(top_5_movies), figsize=(15, 5))
for i, (ax, image_id) in enumerate(zip(axs.flat, top_5_movies)):
img = f"/mnt/metaverse-nas/movielens/mlp-20m/MLP-20M/{image_id}.jpg"
if os.path.exists(img):
ax.imshow(imread(img))
ax.set_aspect("equal")
ax.set_title(os.path.basename(img).split(".")[0])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.subplots_adjust(wspace=0, hspace=0)
plt.show()

Pretty expected list imo! In the next section, we will calculate the Ranking Quality metrics to see relative performance of our transformer model vs the popular movie heuristics.
We will assume that the model will return K items (movies) based on a score for a few values of K - let’s say K = 3, 5, 10. We will measure the ranking quality of these K items based on the relevant items returned.
Let’s first test our code on a small batch.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
k_values = [3, 5, 10]
batch_size = 4
sequence_length = 5
valid_dataset = MovieLensSequenceDataset(
movies_file="./data/ml-1m/movies.dat",
users_file="./data/ml-1m/users.dat",
ratings_file="./data/ml-1m/ratings.dat",
sequence_length=sequence_length,
window_size=1,
is_validation=True,
)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True)
torch.random.manual_seed(3128)
valid_batch = next(iter(valid_dataloader))
(
movie_id_tokens,
rating_id_tokens,
user_id_tokens,
output_movie_id_tokens,
output_rating_id_tokens,
) = valid_batch
print(movie_id_tokens)
print(output_movie_id_tokens)
1
2
3
4
5
6
7
8
9
10
11
2024-09-01 08:04:59.132 | INFO | data:__init__:89 - Creating MovieLensSequenceDataset with validation set: %s
2024-09-01 08:04:59.132 | INFO | data:read_movielens_data:12 - Reading data from files
2024-09-01 08:05:00.844 | INFO | data:_add_tokens:140 - Adding tokens to data
2024-09-01 08:05:00.882 | INFO | data:_generate_sequences:159 - Generating sequences
2024-09-01 08:05:01.544 | INFO | data:__init__:110 - Train data length: 883799
2024-09-01 08:05:01.544 | INFO | data:__init__:111 - Validation data length: 98290
tensor([[1360, 2314, 2313, 3621, 1192],
[3682, 3441, 1539, 263, 520],
[1227, 1264, 901, 1247, 3366],
[1353, 1178, 257, 1220, 1250]], dtype=torch.int32)
tensor([1271, 3724, 1232, 1196], dtype=torch.int32)
For getting the movie predictions from our model, we have added a new function.
NOTE: Remember we had some duplicates (pre-watched movies) in the predictions. We will remove them before calculating the metrics i.e. we will consider logits for only those movies that are not in the context window.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def get_model_predictions(
model: nn.Module,
movie_id_tokens: torch.Tensor,
user_id_tokens: torch.Tensor,
n: int,
):
with torch.no_grad():
# batch x num_tokens
output = model(movie_id_tokens, user_id_tokens)
# get top k predictions
# we work with the top n + movie_id_tokens.shape[-1] to ensure
# that we do not recommended the movies that the user has already seen
_, top_tokens = output.topk(n + movie_id_tokens.shape[-1], dim=-1)
for row in range(top_tokens.shape[0]):
merged, counts = torch.cat((top_tokens[row], movie_id_tokens[row])).unique(
return_counts=True
)
intersection = merged[torch.where(counts.gt(1))]
top_tokens[row, :n] = top_tokens[row][
torch.isin(top_tokens[row], intersection, invert=True)
][:n]
return top_tokens[:, :n]
To generate the relevancy of the output, we have another function:
1
2
def calculate_relevance(predictions, targets):
return (predictions == targets.unsqueeze(1)).float()
Now, let’s calculate the metrics for this small batch:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
for k in k_values:
baseline_reciprocal_rank = torch.zeros(batch_size)
model_reciprocal_rank = torch.zeros(batch_size)
popular_movies_df = get_popular_movies(
ratings_file="./data/ml-1m/ratings.dat", n=k + sequence_length
)
baseline_predictions = get_popular_movie_predictions(
popular_movies_df, movie_id_tokens, n=k, batch_size=batch_size
)
model_predictions = get_model_predictions(
trained_model, movie_id_tokens, user_id_tokens, n=k
)
baseline_relevance = calculate_relevance(
baseline_predictions.predictions, output_movie_id_tokens
)
model_relevance = calculate_relevance(
model_predictions.predictions, output_movie_id_tokens
)
baseline_relevant_index = torch.where(baseline_relevance == 1)
model_relevant_index = torch.where(model_relevance == 1)
# calculate the metrics
baseline_reciprocal_rank[baseline_relevant_index[0]] = 1 / (
baseline_relevant_index[1].float() + 1
)
model_reciprocal_rank[model_relevant_index[0]] = 1 / (
model_relevant_index[1].float() + 1
)
print(f"Reciprocal Rank @ {k}: Baseline: {baseline_reciprocal_rank.mean()}")
print(f"Reciprocal Rank @ {k}: Model: {model_reciprocal_rank.mean()}")
# Calculate the mean average precision
# since there could only be one relevant item in the predictions
# precision = relevance_for_row.sum() / k
baseline_map = baseline_relevance.sum(dim=1) / k
model_map = model_relevance.sum(dim=1) / k
print(f"Mean Average Precision @ {k}: Baseline: {baseline_map.mean()}")
print(f"Mean Average Precision @ {k}: Model: {model_map.mean()}")
# Calculate the NDCG
baseline_ndcg = ndcg_score(baseline_relevance, baseline_predictions.scores, k=k)
model_ndcg = ndcg_score(model_relevance, model_predictions.scores, k=k)
print(f"NDCG @ {k}: Baseline: {baseline_ndcg}")
print(f"NDCG @ {k}: Model: {model_ndcg}")
print("---------------------------------------------------")
Here are the predicted tokens for k = 10. k = 3, 5 are just a subset of this.
1
2
3
4
5
print(output_movie_id_tokens)
print(baseline_predictions.predictions)
print(model_predictions.predictions)
print(baseline_relevance)
print(model_relevance)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
tensor([1182, 2847, 352, 551], dtype=torch.int32)
tensor([[ 318, 858, 50, 527, 1198, 260, 750, 912, 2762, 1193],
[ 318, 858, 50, 527, 1198, 260, 750, 912, 2762, 1193],
[ 318, 858, 50, 527, 1198, 260, 750, 912, 2762, 1193],
[ 318, 858, 50, 527, 1198, 260, 750, 912, 2762, 1193]],
dtype=torch.int32)
tensor([[1931, 588, 2849, 1892, 1899, 2105, 3141, 1226, 1204, 2728],
[1353, 2386, 2847, 1375, 1335, 2571, 1543, 1539, 476, 1607],
[1720, 2677, 1934, 699, 2055, 139, 2075, 10, 1942, 3186],
[1539, 476, 1111, 373, 1255, 2916, 1931, 1355, 724, 2284]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
Based on the above, the results seem reasonable!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Reciprocal Rank @ 3: Baseline: 0.0
Reciprocal Rank @ 3: Model: 0.125
Mean Average Precision @ 3: Baseline: 0.0
Mean Average Precision @ 3: Model: 0.0833333358168602
NDCG @ 3: Baseline: 0.0
NDCG @ 3: Model: 0.15773243839286433
---------------------------------------------------
Reciprocal Rank @ 5: Baseline: 0.0
Reciprocal Rank @ 5: Model: 0.125
Mean Average Precision @ 5: Baseline: 0.0
Mean Average Precision @ 5: Model: 0.05000000074505806
NDCG @ 5: Baseline: 0.0
NDCG @ 5: Model: 0.15773243839286433
---------------------------------------------------
Reciprocal Rank @ 10: Baseline: 0.0
Reciprocal Rank @ 10: Model: 0.1840277761220932
Mean Average Precision @ 10: Baseline: 0.0
Mean Average Precision @ 10: Model: 0.07500000298023224
NDCG @ 10: Baseline: 0.0
NDCG @ 10: Model: 0.31185615650529175
---------------------------------------------------
Great! Let’s add a function for this and generate for the full validation set. You can find this function in eval.py.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
batch_size = 512
sequence_length = 5
valid_dataset = MovieLensSequenceDataset(
movies_file="./data/ml-1m/movies.dat",
users_file="./data/ml-1m/users.dat",
ratings_file="./data/ml-1m/ratings.dat",
sequence_length=sequence_length,
window_size=1,
is_validation=True,
)
# shuffle doesnt matter for calculating metrics
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)
metrics = {}
for k in k_values:
# we would torch.cat these later
baseline_relevances = []
model_relevances = []
baseline_scores = []
model_scores = []
popular_movies_df = get_popular_movies(
ratings_file="./data/ml-1m/ratings.dat", n=k + sequence_length
)
for batch in valid_dataloader:
(
movie_id_tokens,
rating_id_tokens,
user_id_tokens,
output_movie_id_tokens,
output_rating_id_tokens,
) = batch
baseline_predictions = get_popular_movie_predictions(
popular_movies_df, movie_id_tokens, n=k, batch_size=movie_id_tokens.shape[0]
)
model_predictions = get_model_predictions(
trained_model, movie_id_tokens, user_id_tokens, n=k
)
baseline_relevance = calculate_relevance(
baseline_predictions.predictions, output_movie_id_tokens
)
model_relevance = calculate_relevance(
model_predictions.predictions, output_movie_id_tokens
)
baseline_relevances.append(baseline_relevance)
model_relevances.append(model_relevance)
baseline_scores.append(baseline_predictions.scores)
model_scores.append(model_predictions.scores)
baseline_relevances_tensor = torch.cat(baseline_relevances)
model_relevances_tensor = torch.cat(model_relevances)
baseline_scores_tensor = torch.cat(baseline_scores)
model_scores_tensor = torch.cat(model_scores)
# Calculate the metrics
baseline_metrics = calculate_metrics(
baseline_relevances_tensor, baseline_scores_tensor
)
model_metrics = calculate_metrics(model_relevances_tensor, model_scores_tensor)
metrics[k] = (baseline_metrics, model_metrics)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
metrics_df = pd.DataFrame(
[
{
"k": k,
"baseline_mrr": v[0].MRR,
"model_mrr": v[1].MRR,
"baseline_map": v[0].MAP,
"model_map": v[1].MAP,
"baseline_ndcg": v[0].NDCG,
"model_ndcg": v[1].NDCG,
}
for k, v in metrics.items()
]
)
print(metrics_df.to_markdown())
| k | baseline_mrr | model_mrr | baseline_map | model_map | baseline_ndcg | model_ndcg | |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 0.000148018 | 0.0790383 | 0.000183747 | 0.120252 | 0.000157374 | 0.0895683 |
| 1 | 5 | 0.000253162 | 0.0915386 | 0.000622697 | 0.175549 | 0.000342393 | 0.112223 |
| 2 | 10 | 0.000517913 | 0.10491 | 0.00278682 | 0.277059 | 0.00101894 | 0.144872 |
Results
From the results, we can see that our model is orders of magnitude better than just suggesting the top k movies by ratings - ranging 100x to 500x depending on the metric and k.
Next steps
There are several ways to improve the model further. For example,
- We have only used the movie ids to make these predictions. We have not used any of the dense features or textual information for the model. We can improve the model by adding dense layers to feed these features.
- We have not accounted for repetitions in the predictions. We can handle that by penalizing token predictions that are repeated.
- We can use the ratings to re-weight loss values to account for the quantification of “liking the movie”.
- Improve model training and eval performance by using
torch.compile - And several other ways
But, this post is already getting too big so these follow up will need to wait for another day.
Conclusion
In this post, we have built a transformer model for next token prediction for movie recommendations. We have trained the model and evaluated the model using ranking quality metrics. We have seen that the model is significantly better than the baseline model.
Comments powered by Disqus.