Exploring GPT2 (Part 1)
Writing GPT2 from scratch and assigning weights from pre-trained Huggingface model
In this post, I will explore the GPT-2 model from Huggingface (HF). This is inspired by Andrej Karpathy’s recent YT video. However, I will try to write the GPT-2 model from scratch first without matching the structure defined by HF model and try to make names a bit more descriptive.
In addition, we would try to match the Huggingface training model with dropouts at appropriate points in the network.
So, let’s start:
1
2
3
4
5
6
7
8
import math
from dataclasses import dataclass
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import GPT2Tokenizer, GPT2LMHeadModel
from transformers import pipeline, set_seed
Let’s take the Huggingface GPT2 transformers model for a spin.
1
2
3
4
5
6
7
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
print("=== encoded input ===")
print(encoded_input)
_ = model(**encoded_input)
1
2
=== encoded input ===
{'input_ids': tensor([[3041, 5372, 502, 416, 597, 2420, 345, 1549, 588, 13]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
Let’s use the model directly for some text generation
1
2
3
4
generator = pipeline('text-generation', model='gpt2')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
1
2
3
4
5
[{'generated_text': "Hello, I'm a language model, but what I'm really doing is making a human-readable document. There are other languages, but those are"},
{'generated_text': "Hello, I'm a language model, not a syntax model. That's why I like it. I've done a lot of programming projects.\n"},
{'generated_text': "Hello, I'm a language model, and I'll do it in no time!\n\nOne of the things we learned from talking to my friend"},
{'generated_text': "Hello, I'm a language model, not a command line tool.\n\nIf my code is simple enough:\n\nif (use (string"},
{'generated_text': "Hello, I'm a language model, I've been using Language in all my work. Just a small example, let's see a simplified example."}]
We can look at the raw parameter dimensions from the published model on huggingface.
1
2
3
parameters_state_dict = model.state_dict()
for key, value in parameters_state_dict.items():
print(key, value.size())
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
transformer.wte.weight torch.Size([50257, 768])
transformer.wpe.weight torch.Size([1024, 768])
transformer.h.0.ln_1.weight torch.Size([768])
transformer.h.0.ln_1.bias torch.Size([768])
transformer.h.0.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.0.attn.c_attn.bias torch.Size([2304])
transformer.h.0.attn.c_proj.weight torch.Size([768, 768])
transformer.h.0.attn.c_proj.bias torch.Size([768])
transformer.h.0.ln_2.weight torch.Size([768])
transformer.h.0.ln_2.bias torch.Size([768])
transformer.h.0.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.0.mlp.c_fc.bias torch.Size([3072])
transformer.h.0.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.0.mlp.c_proj.bias torch.Size([768])
...truncated...
transformer.h.11.ln_1.weight torch.Size([768])
transformer.h.11.ln_1.bias torch.Size([768])
transformer.h.11.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.11.attn.c_attn.bias torch.Size([2304])
transformer.h.11.attn.c_proj.weight torch.Size([768, 768])
transformer.h.11.attn.c_proj.bias torch.Size([768])
transformer.h.11.ln_2.weight torch.Size([768])
transformer.h.11.ln_2.bias torch.Size([768])
transformer.h.11.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.11.mlp.c_fc.bias torch.Size([3072])
transformer.h.11.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.11.mlp.c_proj.bias torch.Size([768])
transformer.ln_f.weight torch.Size([768])
transformer.ln_f.bias torch.Size([768])
lm_head.weight torch.Size([50257, 768])
GPT2 Architecture
In the above architecture, we can identify different layers as:
wteandwpeare the token and position embeddings, respectivelyh.<N>represents attention blocks. Each attention block has 4 sub-layersln_1: LayerNorm 1 (i.e. pre attention). Note that GPT2 changed the order of LayerNorm in the decoder layer to move it before attention and MLPattn: attention layerln_2: LayerNorm 2 (i.e. pre MLP)mlp: Multi Layer Perceptron in each decoder block
ln_fis the final LayerNorm that is added after all the decoder attention blocks
Extract from GPT-2 paper that highlights the changes:

Based on the description, we can generate the GPT-2 architecture diagram
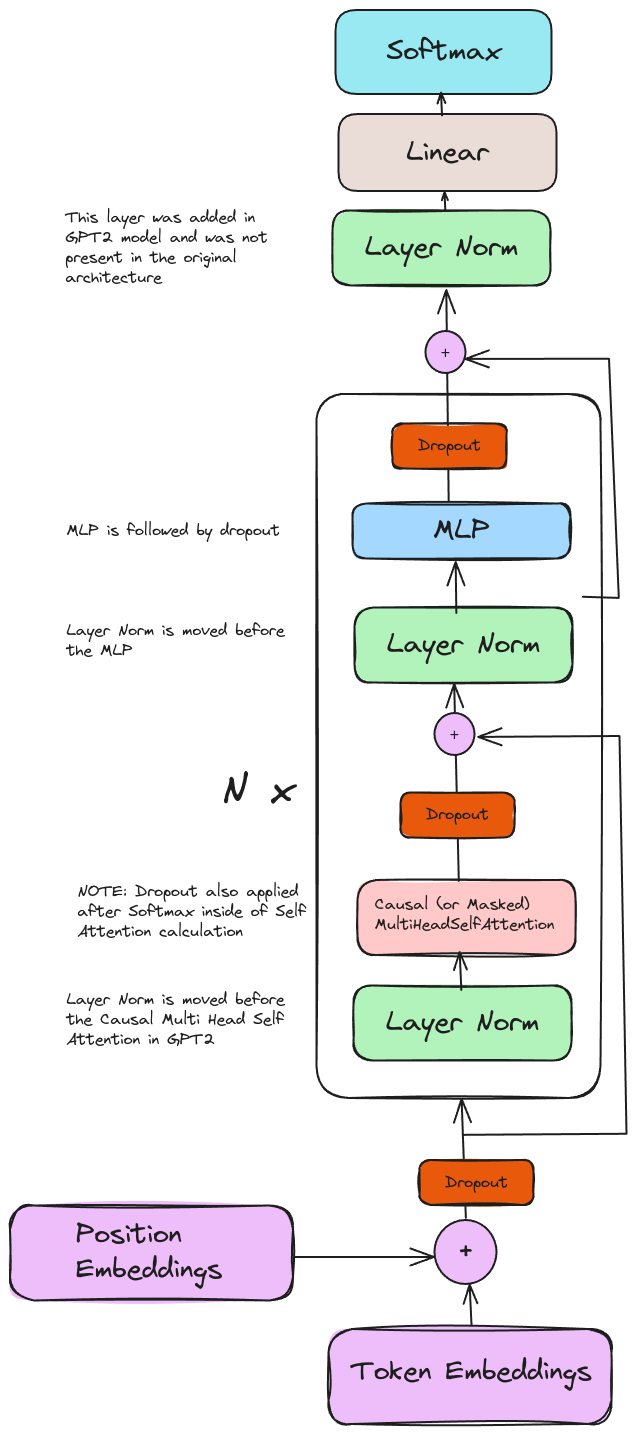
Model Definition
Next, we will define the GPT2 model from scratch. We will start by defining the model configuration and then define the model layer by layer.
First, let’s look at the GPT-2 PyTorch model from Huggingface.
1
print(model)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-11): 12 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
)
We can see that the model consists of:
- Token and Position embeddings
- Multiple GPT2 blocks
- LayerNorm at the end
- Linear layer for output
GPT2 Model Config
Initially, we will create a model config that has all the hyperparameters for the model.
1
2
3
4
5
6
7
8
9
10
11
@dataclass
class GPT2Config:
vocab_size: int = 50257
context_window_size: int = 1024
embedding_dimension: int = 768
num_layers: int = 12
num_heads: int = 12
dropout_embeddings: float = 0.1
dropout_attention: float = 0.1
dropout_residual: float = 0.1
layer_norm_epsilon: float = 1e-5
Note the dropout probabilities. Based on the original transformers paper, the dropout probabilities are set to 0.1 for embeddings, attention, and residual connections.

Model Skeleton
Using the above config, let us define the GPT2 model skeleton:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class GPT2(nn.Module):
def __init__(self, config: GPT2Config, device: str = 'cpu'):
super().__init__()
self.config = config
self.token_embedding = nn.Embedding(config.vocab_size,
config.embedding_dimension)
self.positional_embedding = nn.Embedding(config.context_window_size,
config.embedding_dimension)
self.positional_ids = torch.arange(
config.context_window_size).unsqueeze(0).to(device)
self.embedding_dropout = nn.Dropout(config.dropout_embeddings)
# =====
# TODO: Implement GPT2Layer Module
# =====
self.layers = nn.ModuleList(
[GPT2Layer(config) for _ in range(config.num_layers)])
self.layer_norm = nn.LayerNorm(config.embedding_dimension)
# gpt2 does not use a bias in the output layer
self.output_layer = nn.Linear(config.embedding_dimension,
config.vocab_size, bias=False)
def forward(self, input_ids: torch.Tensor):
_, current_sequence_length = input_ids.size()
positions = self.positional_ids[:, :current_sequence_length]
embeddings = self.token_embedding(
input_ids) + self.positional_embedding(positions)
embeddings = self.embedding_dropout(embeddings)
for layer in self.layers:
embeddings = layer(embeddings)
embeddings = self.layer_norm(embeddings)
return self.output_layer(embeddings) # returns logits
The GPT2 model consists of token embeddings, positional embeddings, multiple GPT2 layers, layer normalization, and an output layer. GPT2 model takes input_ids as input and performs the following steps:
- Embeds the input_ids using token embeddings and positional embeddings.
- Applies dropout to regularize the embeddings before applying attention
- Passes the embeddings through each GPT2 Decoder layer.
- Applies layer normalization to the final embeddings.
- Passes the normalized embeddings through the output layer to get logits.
We still need to define the GPT2Layer. Let’s do that now.
GPT2 Layer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class GPT2Layer(nn.Module):
def __init__(self, config: GPT2Config):
super().__init__()
self.layer_norm1 = nn.LayerNorm(config.embedding_dimension)
# =====
# TODO: Implement CausalMultiHeadAttention Module
# =====
self.attention = CausalMultiHeadAttention(config)
self.layer_norm2 = nn.LayerNorm(config.embedding_dimension)
# =====
# TODO: Implement MLP Module
# =====
self.mlp = MLP(config)
def forward(self, embeddings: torch.Tensor):
attention_output = embeddings + self.attention(
self.layer_norm1(embeddings))
mlp_output = attention_output + self.mlp(
self.layer_norm2(attention_output))
return mlp_output
Let’s zoom into the GPT2Layer module.
- Input embeddings are passed through a layer normalization layer, then through the self-attention mechanism.
- Output of the self-attention mechanism is added to the input embeddings to form the attention_output as a residual connection
- The attention_output is then passed through another layer normalization layer and a multi-layer perceptron (MLP)
- Output from mlp is added to the attention_output to form the mlp_output as another residual connection
- The mlp_output is then fed into the next GPT2Layer (or the final layer norm in the case of the last layer)
Next, we need to implemented CausalMultiHeadAttention and MLP modules. Let’s define the MLP module first:
1
2
3
4
5
6
7
8
9
10
11
12
13
class MLP(nn.Module):
def __init__(self, config: GPT2Config):
super().__init__()
self.fc1 = nn.Linear(config.embedding_dimension,
4 * config.embedding_dimension)
# the approximated gelu is only needed to match the outputs perfectly with the huggingface model
self.activation = nn.GELU(approximate="tanh")
self.fc2 = nn.Linear(4 * config.embedding_dimension,
config.embedding_dimension)
self.dropout = nn.Dropout(config.dropout_residual)
def forward(self, x: torch.Tensor):
return self.dropout(self.fc2(self.activation(self.fc1(x))))
NOTE: We use the approximated gelu to match the outputs perfectly with the Huggingface model.
This is pretty straight-forward. It is a 2 layer MLP with a GELU activation in between. For more details on GELU, go to original paper - GAUSSIAN ERROR LINEAR UNITS.
Now, let’s implement the final piece - CausalMultiHeadAttention. For attention calculation, we will use the flash attention implementation provided by pytorch.
Causal Multi Head Attention
Why Causal? In the context of language modeling (Text Generation) using decoder-only transformers, we want to ensure that the model does not look into the future. This is achieved by masking the attention weights to ensure that the model only attends to the previous tokens in the sequence.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class CausalMultiHeadAttention(nn.Module):
def __init__(self, config: GPT2Config):
super().__init__()
self.num_heads = config.num_heads
self.embedding_dimension = config.embedding_dimension
self.head_dim = self.embedding_dimension // self.num_heads
assert self.head_dim * self.num_heads == self.embedding_dimension, \
"embedding_dimension must be divisible by num_heads"
self.qkv = nn.Linear(self.embedding_dimension,
3 * self.embedding_dimension)
self.out = nn.Linear(self.embedding_dimension, self.embedding_dimension)
self.attention_dropout_p = config.dropout_attention
self.residual_dropout = nn.Dropout(config.dropout_residual)
def forward(self, x: torch.Tensor):
batch_size, sequence_length, _ = x.size()
qkv = self.qkv(x)
q, k, v = qkv.split(self.embedding_dimension,
dim=2) # split along the third dimension
k = k.view(batch_size, sequence_length, self.num_heads,
self.head_dim).permute(0, 2, 1, 3)
v = v.view(batch_size, sequence_length, self.num_heads,
self.head_dim).permute(0, 2, 1, 3)
q = q.view(batch_size, sequence_length, self.num_heads,
self.head_dim).permute(0, 2, 1, 3)
weights = F.scaled_dot_product_attention(
q, k, v, is_causal=True,
dropout_p=self.attention_dropout_p if self.training else 0.0)
output = weights.transpose(1, 2).contiguous().view(
batch_size, sequence_length, self.embedding_dimension)
output = self.out(output)
output = self.residual_dropout(output)
return output
In the above code, we define the CausalMultiHeadAttention module. This module performs the following steps:
- Takes the input embeddings and passes them through a linear layer to get the query, key, and value tensors.
- Splits the query, key, and value tensors into multiple heads.
- Computes the attention weights using the scaled dot product attention mechanism.
- We pass the is_causal=True to ensure that the model does not look into the future.
- We also apply dropout to the attention weights.
- Attention weights then go through a linear layer.
- Note the residual dropout is applied to the output of the attention layer.
What does scaled_dot_product_attention do?
Spelled out in code, the scaled dot product attention is fused version of
qkv = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)weights = F.softmax(qkv, dim=-1)weights = F.dropout(weights, p=dropout_p, training=self.training)output = torch.matmul(weights, v)TIP: Read Flash Attention
Testing the Model
At this point, we should be at least be able to call the GPT2 model and get some output.
The weights are randomly initialized so the output will be garbage, but we will tackle that later.
1
2
3
4
5
gpt2_model = GPT2(GPT2Config())
gpt2_out = gpt2_model(encoded_input['input_ids'])
print(gpt2_out.size())
# torch.Size([1, 10, 50257])
Nice! so we are able to call the model e2e.
Now starts the fun part. We should now be able to take the weights from the Huggingface model and apply them to the model we just defined.
Let’s first print all the parameter keys and dimensions and match it against the Huggingface model:
1
2
3
4
assert len(gpt2_model.state_dict().items()) == len(model.state_dict().items())
for (key, value), (ref_key, ref_value) in zip(gpt2_model.state_dict().items(), model.state_dict().items()):
print(key, value.size(), "<>", ref_key, ref_value.size())
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
token_embedding.weight torch.Size([50257, 768]) <> transformer.wte.weight torch.Size([50257, 768])
positional_embedding.weight torch.Size([1024, 768]) <> transformer.wpe.weight torch.Size([1024, 768])
layers.0.layer_norm1.weight torch.Size([768]) <> transformer.h.0.ln_1.weight torch.Size([768])
layers.0.layer_norm1.bias torch.Size([768]) <> transformer.h.0.ln_1.bias torch.Size([768])
layers.0.attention.qkv.weight torch.Size([2304, 768]) <> transformer.h.0.attn.c_attn.weight torch.Size([768, 2304])
layers.0.attention.qkv.bias torch.Size([2304]) <> transformer.h.0.attn.c_attn.bias torch.Size([2304])
layers.0.attention.out.weight torch.Size([768, 768]) <> transformer.h.0.attn.c_proj.weight torch.Size([768, 768])
layers.0.attention.out.bias torch.Size([768]) <> transformer.h.0.attn.c_proj.bias torch.Size([768])
layers.0.layer_norm2.weight torch.Size([768]) <> transformer.h.0.ln_2.weight torch.Size([768])
layers.0.layer_norm2.bias torch.Size([768]) <> transformer.h.0.ln_2.bias torch.Size([768])
layers.0.mlp.fc1.weight torch.Size([3072, 768]) <> transformer.h.0.mlp.c_fc.weight torch.Size([768, 3072])
layers.0.mlp.fc1.bias torch.Size([3072]) <> transformer.h.0.mlp.c_fc.bias torch.Size([3072])
layers.0.mlp.fc2.weight torch.Size([768, 3072]) <> transformer.h.0.mlp.c_proj.weight torch.Size([3072, 768])
layers.0.mlp.fc2.bias torch.Size([768]) <> transformer.h.0.mlp.c_proj.bias torch.Size([768])
...truncated...
layers.11.layer_norm1.weight torch.Size([768]) <> transformer.h.11.ln_1.weight torch.Size([768])
layers.11.layer_norm1.bias torch.Size([768]) <> transformer.h.11.ln_1.bias torch.Size([768])
layers.11.attention.qkv.weight torch.Size([2304, 768]) <> transformer.h.11.attn.c_attn.weight torch.Size([768, 2304])
layers.11.attention.qkv.bias torch.Size([2304]) <> transformer.h.11.attn.c_attn.bias torch.Size([2304])
layers.11.attention.out.weight torch.Size([768, 768]) <> transformer.h.11.attn.c_proj.weight torch.Size([768, 768])
layers.11.attention.out.bias torch.Size([768]) <> transformer.h.11.attn.c_proj.bias torch.Size([768])
layers.11.layer_norm2.weight torch.Size([768]) <> transformer.h.11.ln_2.weight torch.Size([768])
layers.11.layer_norm2.bias torch.Size([768]) <> transformer.h.11.ln_2.bias torch.Size([768])
layers.11.mlp.fc1.weight torch.Size([3072, 768]) <> transformer.h.11.mlp.c_fc.weight torch.Size([768, 3072])
layers.11.mlp.fc1.bias torch.Size([3072]) <> transformer.h.11.mlp.c_fc.bias torch.Size([3072])
layers.11.mlp.fc2.weight torch.Size([768, 3072]) <> transformer.h.11.mlp.c_proj.weight torch.Size([3072, 768])
layers.11.mlp.fc2.bias torch.Size([768]) <> transformer.h.11.mlp.c_proj.bias torch.Size([768])
layer_norm.weight torch.Size([768]) <> transformer.ln_f.weight torch.Size([768])
layer_norm.bias torch.Size([768]) <> transformer.ln_f.bias torch.Size([768])
output_layer.weight torch.Size([50257, 768]) <> lm_head.weight torch.Size([50257, 768])
Loading pre-trained weights
We can see that number of parameters and dimensions match. In some cases, we notice that the dimensions are transposed as Andrej mentioned in his YouTube video as well.
HF model uses
nn.Conv1dfor qkv projection while we usenn.Linear. Hence, we need to transpose some of these arguments.
Let’s write a method to load all the weights. For the follow-up work, I have moved the existing code to a module gpt.py in the same directory. So, we will just add a classmethod to it. This is what the classmethod looks like
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
...
@classmethod
def from_pretrained(cls) -> 'GPT2':
model_hf = GPT2LMHeadModel.from_pretrained(
'gpt2', resume_download=None)
config = GPT2Config()
model = cls(config)
with torch.no_grad():
model.token_embedding.weight.copy_(model_hf.transformer.wte.weight)
model.positional_embedding.weight.copy_(
model_hf.transformer.wpe.weight)
for layer_idx in range(len(model.layers)):
model.layers[layer_idx].layer_norm1.weight.copy_(
model_hf.transformer.h[layer_idx].ln_1.weight)
model.layers[layer_idx].layer_norm1.bias.copy_(
model_hf.transformer.h[layer_idx].ln_1.bias)
# HF model uses Conv1d for qkv projection, we use linear.
# hence the transpose
model.layers[layer_idx].attention.qkv.weight.copy_(
model_hf.transformer.h[layer_idx].attn.c_attn.weight.t())
model.layers[layer_idx].attention.qkv.bias.copy_(
model_hf.transformer.h[layer_idx].attn.c_attn.bias)
model.layers[layer_idx].attention.out.weight.copy_(
model_hf.transformer.h[layer_idx].attn.c_proj.weight.t())
model.layers[layer_idx].attention.out.bias.copy_(
model_hf.transformer.h[layer_idx].attn.c_proj.bias)
model.layers[layer_idx].layer_norm2.weight.copy_(
model_hf.transformer.h[layer_idx].ln_2.weight)
model.layers[layer_idx].layer_norm2.bias.copy_(
model_hf.transformer.h[layer_idx].ln_2.bias)
model.layers[layer_idx].mlp.fc1.weight.copy_(
model_hf.transformer.h[layer_idx].mlp.c_fc.weight.t())
model.layers[layer_idx].mlp.fc1.bias.copy_(
model_hf.transformer.h[layer_idx].mlp.c_fc.bias)
model.layers[layer_idx].mlp.fc2.weight.copy_(
model_hf.transformer.h[layer_idx].mlp.c_proj.weight.t())
model.layers[layer_idx].mlp.fc2.bias.copy_(
model_hf.transformer.h[layer_idx].mlp.c_proj.bias)
model.layer_norm.weight.copy_(model_hf.transformer.ln_f.weight)
model.layer_norm.bias.copy_(model_hf.transformer.ln_f.bias)
model.output_layer.weight.copy_(model_hf.lm_head.weight)
# output_layer does not have a bias in gpt2
return model
Let’s take this method for a spin.
1
2
3
4
5
6
7
from gpt import GPT2, GPT2Config
gpt2_model = GPT2.from_pretrained()
gpt2_out = gpt2_model(encoded_input['input_ids'])
print(gpt2_out.size())
# torch.Size([1, 10, 50257])
Testing Eval Step
We should be able to test the 2 models for output now. We can feed both the models with a random input and check the final output at the end.
1
2
3
4
5
6
7
8
9
10
11
12
hf_model = GPT2LMHeadModel.from_pretrained('gpt2', resume_download=None)
hf_model.eval()
gpt2_model = GPT2.from_pretrained()
gpt2_model.eval()
torch.random.manual_seed(42)
model_input = torch.randint(0, 50257, (1, 30))
gpt2_output = gpt2_model(model_input)
hf_output = hf_model(model_input)
assert torch.allclose(hf_output.logits, gpt2_output, atol=1e-4)
1
hf_output.logits
1
2
3
4
5
6
7
8
9
10
11
12
13
tensor([[[ -33.4287, -33.3094, -37.3657, ..., -41.1595, -40.2192,
-34.0600],
[ -93.6944, -94.3049, -99.3645, ..., -103.2246, -103.1845,
-97.7775],
[ -76.7458, -77.8964, -84.8150, ..., -86.7074, -86.7198,
-80.1324],
...,
[ -58.4519, -57.2183, -57.8318, ..., -63.7139, -66.0336,
-59.0490],
[ -65.3561, -66.7475, -68.7738, ..., -72.2164, -72.5056,
-66.6998],
[ -58.9639, -59.1462, -59.4149, ..., -62.6749, -64.1926,
-59.5627]]], grad_fn=<UnsafeViewBackward0>)
1
gpt2_output
1
2
3
4
5
6
7
8
9
10
11
12
13
tensor([[[ -33.4287, -33.3094, -37.3657, ..., -41.1595, -40.2192,
-34.0600],
[ -93.6943, -94.3048, -99.3645, ..., -103.2245, -103.1845,
-97.7774],
[ -76.7457, -77.8964, -84.8149, ..., -86.7074, -86.7197,
-80.1324],
...,
[ -58.4519, -57.2183, -57.8318, ..., -63.7139, -66.0336,
-59.0490],
[ -65.3561, -66.7474, -68.7738, ..., -72.2164, -72.5056,
-66.6998],
[ -58.9640, -59.1462, -59.4150, ..., -62.6749, -64.1926,
-59.5627]]], grad_fn=<UnsafeViewBackward0>)
Awesome!! The outputs match within the allowed tolerance. Let’s look at the outputs:
Testing Training Step
In the previous section, we only tested the eval step. A number of dropouts do not run when we run the model in eval model. Let’s switch both models to training mode to see whether they match.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
hf_model = GPT2LMHeadModel.from_pretrained('gpt2', resume_download=None)
hf_model.train()
gpt2_model = GPT2.from_pretrained()
gpt2_model.train()
torch.random.manual_seed(42)
model_input = torch.randint(0, 50257, (1, 10))
# we need to set the manual_seed again to make sure dropouts get the
# same ordered random numbers
torch.random.manual_seed(42)
gpt2_output = gpt2_model(model_input)
# we need to set the manual_seed again to make sure dropouts get the
# same ordered random numbers
torch.random.manual_seed(42)
hf_output = hf_model(model_input)
assert torch.allclose(hf_output.logits, gpt2_output, atol=1e-4)
I added both of the above checks for equivalence as unit tests for gpt module we defined.
1
2
3
4
5
6
7
8
9
10
11
12
-> % pytest -rx -v
============================================================================================================================ test session starts =============================================================================================================================
platform darwin -- Python 3.12.2, pytest-7.4.4, pluggy-1.0.0 -- /Users/kapilsharma/opt/anaconda3/envs/ml-projects/bin/python
cachedir: .pytest_cache
rootdir: /Users/kapilsharma/oss/ml-projects/transformers
plugins: anyio-4.2.0
collected 2 items
test_gpt.py::test_model_correctness_eval PASSED [ 50%]
test_gpt.py::test_model_correctness_train PASSED [100%]
============================================================================================================================= 2 passed in 8.19s ==============================================================================================================================
Summary
We have successfully implemented the GPT2 model from scratch and loaded the weights from the Huggingface model. We have tested the model for both eval and training modes and verified that the outputs match the Huggingface model.
Code and GitHub
All the code for the GPT2 model is available in my transformers’ repository.
Comments powered by Disqus.